大厂如微软是如何通过绑定服务来增强其在内容服务市场中的竞争力的?
参考资料


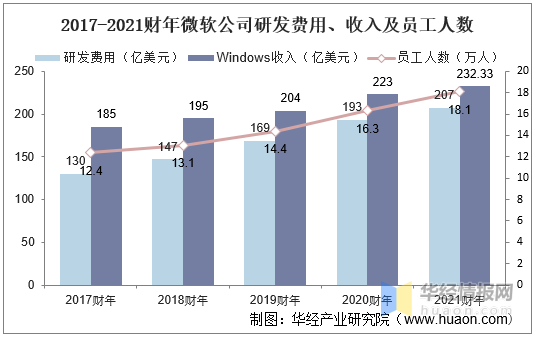

参考资料



Moonshot回答
大厂如微软通过绑定服务增强其在内容服务市场中的竞争力主要体现在以下几个方面:
-
云基础设施服务:微软Azure作为全球第二大云服务厂商,提供云服务市场的重要竞争力量。微软通过不断增强Azure的功能和服务质量,强化了其在内容服务市场的地位。
-
合作伙伴生态:微软在中国市场拥有近17000家专注于不同行业、不同领域的合作伙伴,这些合作伙伴是微软技术在中国市场落地生根的关键。
-
智能云服务:超过95%的世界《财富》500强企业采用了微软智能云服务进行数字化创新,这表明微软在提供企业服务方面具有强大的竞争力。
-
投资和创新:微软对人工智能、机器学习和高级分析的持续投资,确保了其在不断发展的云市场中保持竞争力。
-
内容服务和游戏业务:微软Xbox内容和服务收入的增长,以及通过收购动视暴雪等举措,增强了其在游戏内容服务领域的竞争力。
-
技术和服务的绑定:微软通过将云服务与其软件产品(如Office 365和Windows)深度集成,提供了更加丰富和便捷的用户体验,从而增强了市场竞争力。
-
市场策略:微软采取了积极的市场策略,包括与企业客户建立长期合作关系,提供定制化解决方案,以及通过收购和合作来扩大其服务范围和深度。
通过这些策略和实践,微软成功地在内容服务市场中增强了其竞争力,并保持了其作为行业领导者的地位。