参考资料

参考资料



Moonshot回答
AI通过自然语言处理(NLP)和知识图谱技术对剧本内容进行评估,辅助IP采购和降低项目风险的方式如下:
-
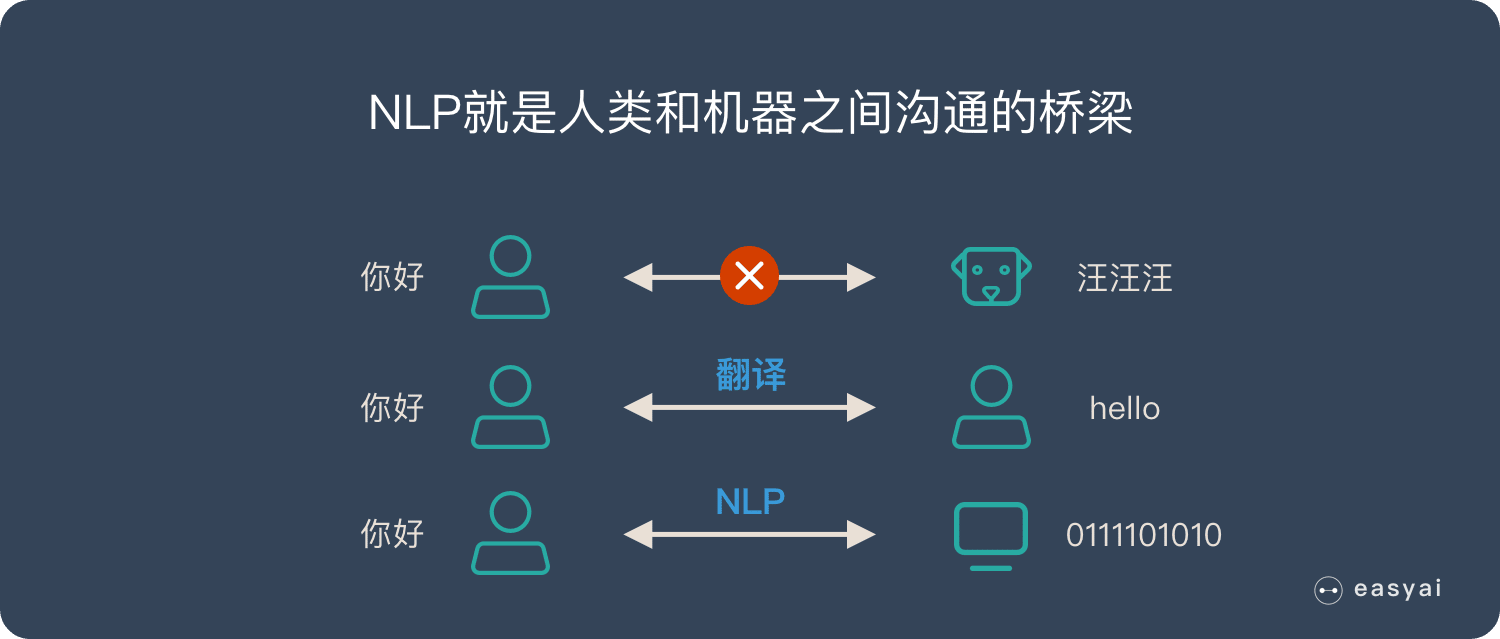
自然语言处理(NLP):AI利用NLP技术理解剧本文本,包括情感分析、主题识别、角色分析、对话流畅性等。例如,ScriptReader.ai和Prescene等工具可以提供剧本的深入分析和建议。
-
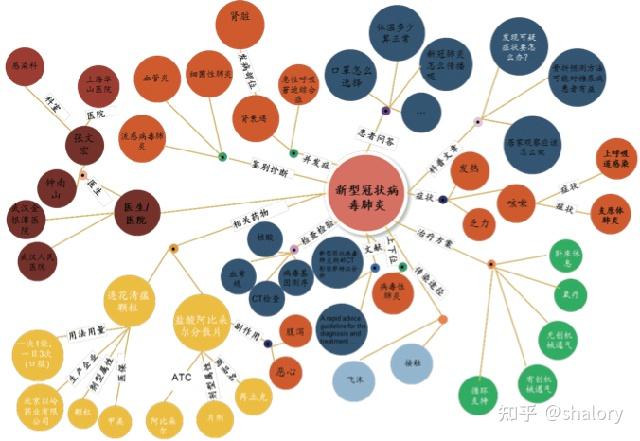
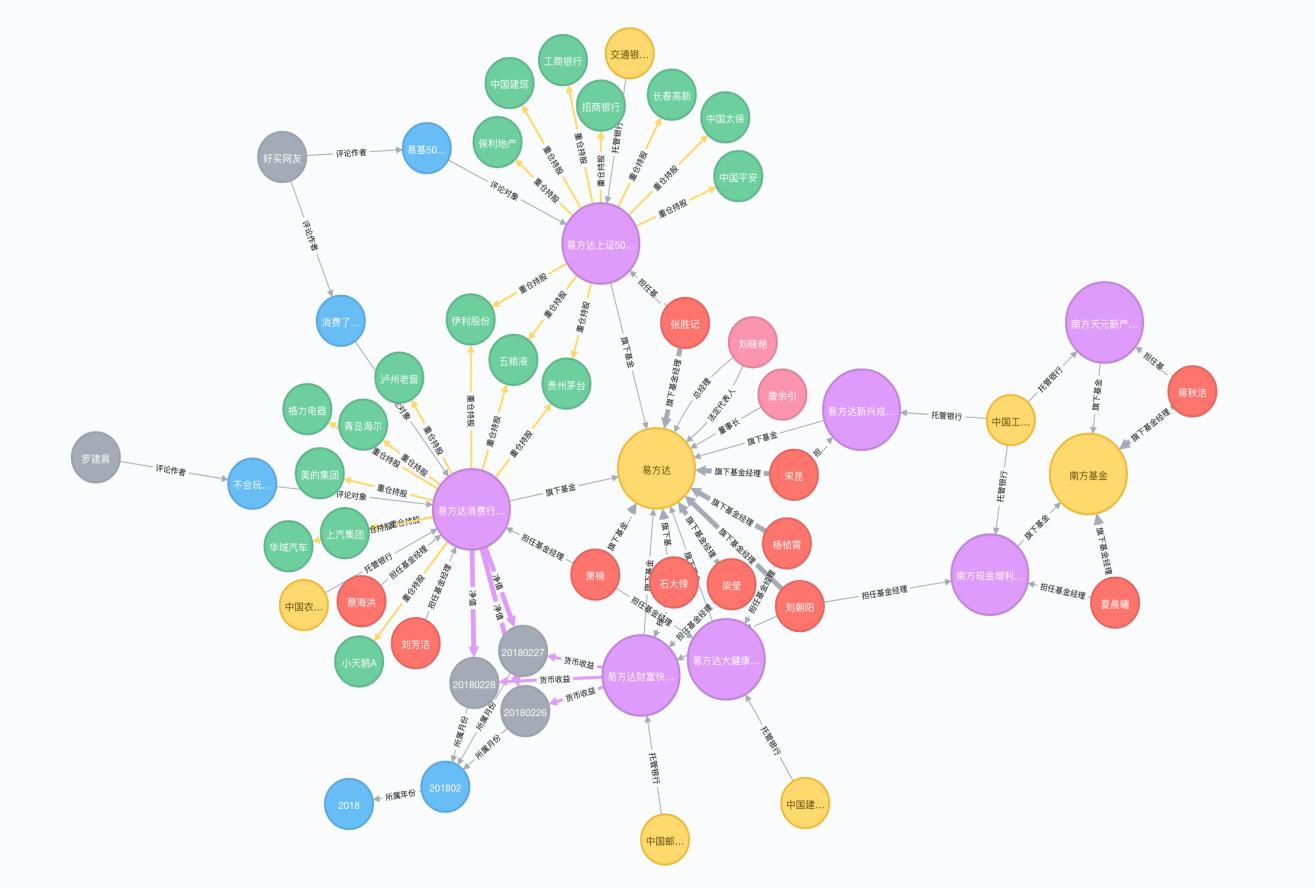
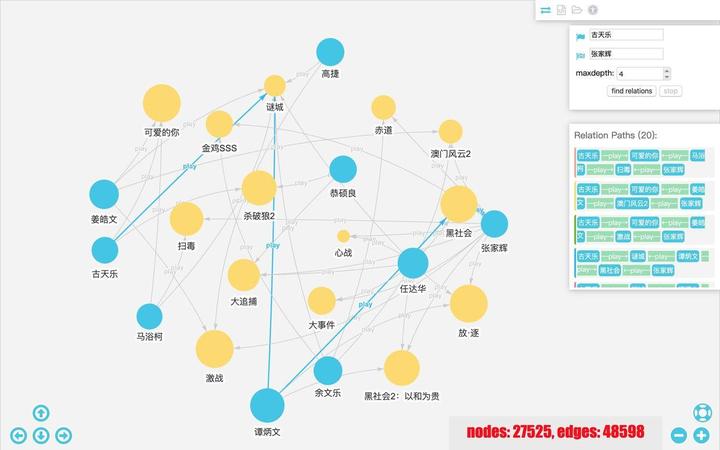
知识图谱:AI构建剧本相关的知识图谱,将剧本中的实体(如角色、地点、事件)和关系(如角色之间的关系、事件的因果关系)进行结构化表示。这有助于分析剧本的复杂性和逻辑一致性。
-
剧本内容评估:AI评估剧本的原创性、市场潜力、受众吸引力等,为IP采购提供数据支持。同时,通过分析剧本中潜在的问题和风险,提前预警,降低项目风险。
-
辅助决策:AI提供剧本改进建议,帮助编剧优化内容,提升剧本质量。此外,AI还可以辅助预算估算、拍摄计划制定等前期制作流程。
综上所述,AI技术在剧本评估和IP采购中发挥重要作用,通过提供深入分析、优化建议和风险预警,帮助影视行业降低成本、提高效率和成功率。
继续提问
相关问题
2022年版《劝服》电影中,弗雷德里克·温特沃斯上校是由谁饰演的,这个角色有什么重要性?
纪尧姆·德尚普利特和戈弗雷·德维尔阿杜因在摩里亚的征服过程中采取了哪些策略?
董袭在濡须之战中为何选择与船同沉,而不是逃生?
鲍德温四世作为麻风病人,他的继承问题如何影响了耶路撒冷王国的政治局势?
突尼斯共产党在1939年和1962年分别遭遇了什么政治挑战?
如何判断未来国有银行股息策略是否会继续对长线资金产生吸引力?
赫拉克洛纳斯被废黜后,他的命运如何?
CC-Link的RAS功能在工业控制系统中如何提高系统的可靠性和可维护性,具体的应用场景有哪些?
法国在第一次世界大战后如何应对国际安全与裁军问题?
相关领域的专家对于讨论中的主要观点有什么看法或争议?