强化学习在微调语言模型时,相比传统的监督学习有哪些优势,为什么它能够在有限标注数据情况下仍然提升模型性能?
参考资料
参考资料


Moonshot回答
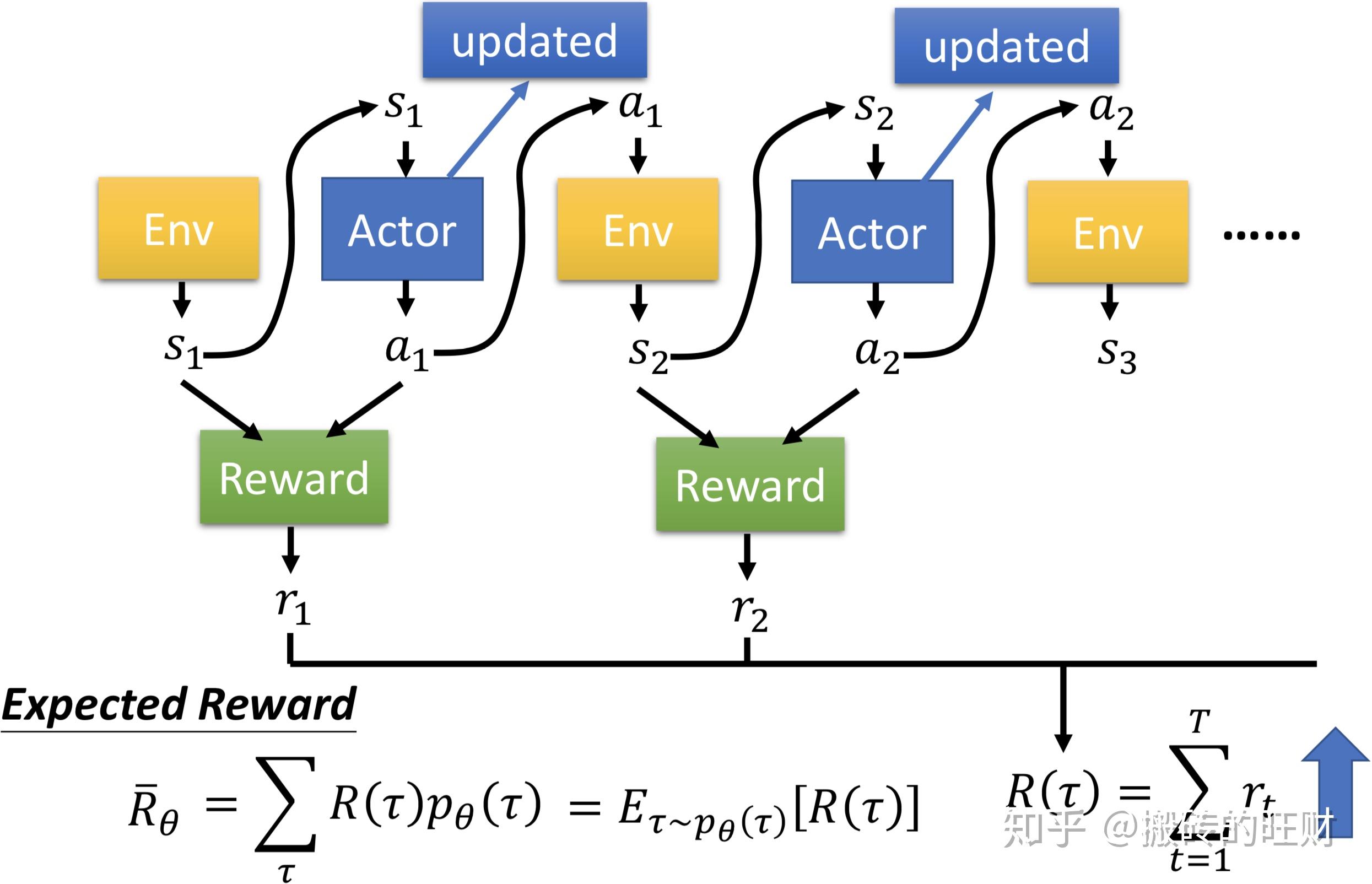
强化学习在微调语言模型时相比传统监督学习具有以下优势:
-
更少的标注数据需求:强化学习通过奖励模型引导模型学习,可以在有限的标注数据下进行有效的学习,而传统监督学习通常需要大量标注数据。
-
动态调整学习策略:强化学习能够根据环境反馈动态调整学习策略,而传统监督学习通常采用固定的学习策略。
-
提高模型的泛化能力:强化学习通过与环境的交互学习,能够提高模型在不同任务和领域的泛化能力。
-
优化模型行为:强化学习通过奖励机制优化模型行为,使其更符合人类的偏好和价值观。
-
提升模型性能:强化学习通过不断试错和学习,能够持续提升模型性能。
强化学习之所以能在有限标注数据情况下提升模型性能,是因为它利用了以下机制:
- 奖励建模:通过奖励模型评估模型输出,引导模型学习。
- 策略优化:通过强化学习算法(如PPO)不断优化模型策略。
- 数据增强:在数据稀缺的情况下,通过生成合成训练数据来扩充数据集。
- 主动学习:选择对模型提升最有帮助的样本进行标注和学习。
综上所述,强化学习通过这些机制和优势,能够在有限标注数据的情况下提升语言模型的性能。