参考资料



参考资料




Moonshot回答
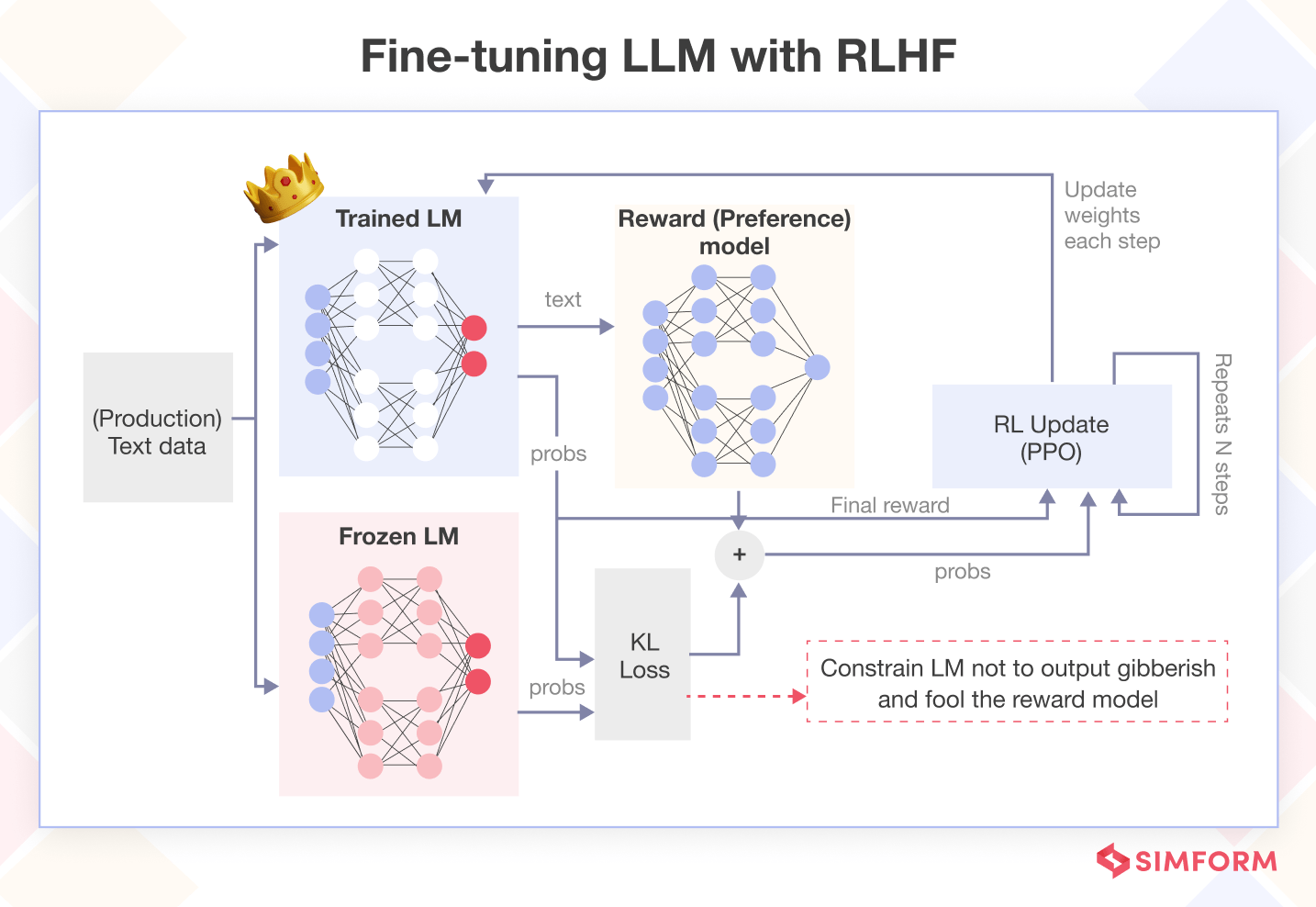
Reinforcement Learning from Human Feedback (RLHF) enhances the training process of conversational AI models like InstructGPT and ChatGPT by incorporating human preferences directly into the model's learning process. This method allows AI to better understand and mimic the nuances of human conversation, leading to more natural and contextually relevant responses.
Key benefits of RLHF include improved accuracy and relevance, adaptability to new information and changing contexts, and human-like interaction capabilities. RLHF is typically employed in four phases: pre-training, preference data collection, reward model training, and RL fine-tuning.
When implementing RLHF, several considerations are crucial:
- Ethical Alignment: Ensuring the AI system aligns with human values and objectives.
- Data Privacy: Safeguarding user data and maintaining privacy during the feedback process.
- Scalability: Designing systems that can handle large volumes of data and feedback efficiently.
- Human-in-the-loop: Involving human evaluators to provide the necessary feedback for training the reward model.
- Reward Model Design: Developing a robust reward model that can accurately translate human preferences into a numerical reward signal.
RLHF has been successfully applied in various domains, including healthcare, entertainment, and education, demonstrating its potential to revolutionize AI interactions. However, it is essential to address the ethical and practical challenges to harness its full potential responsibly.
继续提问
相关问题
如何通过将AI与CRM深度集成来改善数据收集、处理和价值提取的效率?
藤田级数和改良藤田级数,它们如何划分龙卷风的强度?
PowerSchool的综合平台如何最大化全球学习效果,其推动多产品采纳和国际扩展的策略有哪些?
PowerSchool的现有客户基础如何支持其未来十年的双位数增长潜力,同时还有哪些扩展机会?
Fastly的多层服务交付模型是如何提高客户流量管理效率的?
1911年8月24日,成都召開的川路特別股東會緊急大會上,數萬人為何痛哭失聲並全城罷市、罷課、罷税?
《非诚勿扰3》的主题曲叫什么名字,由谁作曲和演唱?
密列奥塞法隆战役为何被认为是拜占庭帝国走向灭亡的决定性失败?
美国和英国在1815年签署根特条约后,进口的英国商品对美国新兴纺织行业有什么影响?
电影《维拉的一生》主要记录了墨西哥革命期间哪位领导人的事迹?