参考资料


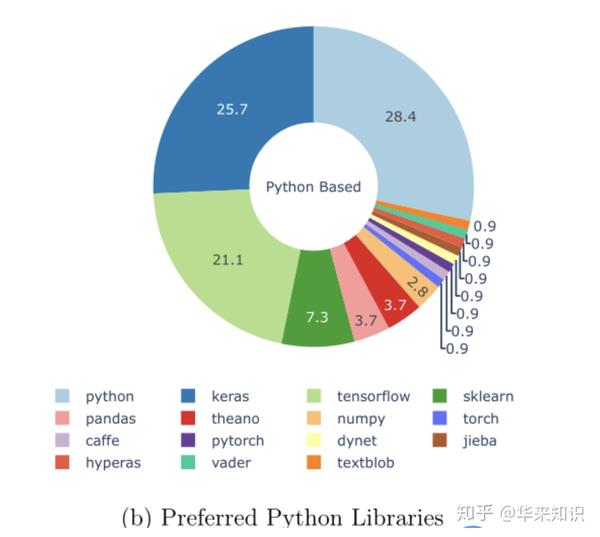
参考资料
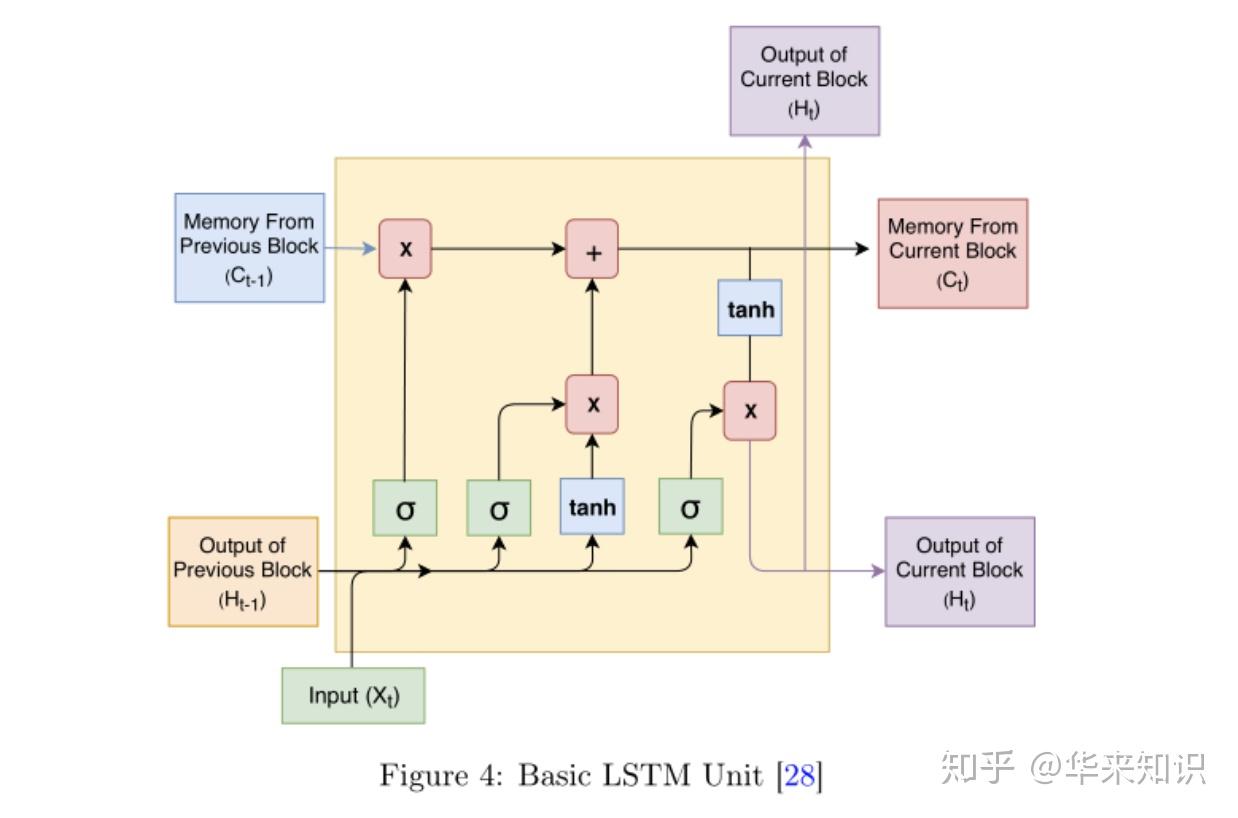
Moonshot回答
在金融市场预测中,使用深度学习模型时,随机数对预测结果的影响主要体现在以下几个方面:
-
初始化权重:深度学习模型在训练开始时需要随机初始化权重。不同的随机数种子会导致不同的初始化状态,这可能会影响模型的收敛速度和最终性能。
-
数据集划分:在训练和测试模型时,数据集通常需要随机划分。随机数种子的不同会影响数据划分的方式,进而影响模型在不同数据子集上的表现。
-
随机梯度下降:在优化模型参数时,随机梯度下降(SGD)等方法会随机选择数据样本进行更新。随机数种子的不同会导致选择的样本序列不同,从而影响模型的学习过程和最终结果。
-
模型的泛化能力:随机数种子的不同可能会使模型在不同的训练集上表现出不同的性能,这有助于评估模型的泛化能力。
-
实验的可重复性:为了确保实验结果的可重复性,研究者通常会固定随机数种子。这有助于在相同的实验条件下复现结果,但也可能限制了模型性能的进一步提升。
-
模型的鲁棒性:模型对随机数种子的敏感性可以作为评估其鲁棒性的一种方式。一个鲁棒的模型应该能够在不同的随机种子下保持稳定的性能。
综上所述,随机数在深度学习模型的训练和预测过程中起着关键作用,它不仅影响模型的初始化和训练过程,还关系到模型的泛化能力和实验的可重复性。因此,在实际应用中,合理选择和设置随机数种子对于提高模型性能和确保结果的可靠性至关重要。
继续提问
相关问题
仰韶文化的早期和中期有哪些重要的考古遗址?
王粲为何被称为“建安七子之冠冕”?
塞勒姆在早期历史中的重要性体现在哪些方面,尤其是在美国清教徒和新英格兰历史中的地位?
What are the main differences between the GPT-2, GPT-3, and GPT-4 models, and how have these differe
怎样整理家庭财务档案对理财有什么实际好处,如何开始这一过程?
希斯·莱杰在《黑暗骑士》中饰演了哪个角色?
M82 X-1是如何被观测到并确认其存在的?
熊梓淇的经纪公司名称是什么?
哪些与鬼魂复仇相关的高棉民间故事?
《伊朗式分居》主要讲述了什么样的故事情节?